CSV delimiter confusion
Comma-separated values (CSV) files don’t always use commas 2021-12-07 #data

- CSV delimiters ←
- CSV character encoding
- Why CSV survives
- RFC-4180 compliant CSV
- CSV on the Web (CSVW)
- Excel’s broken CSV
Comma-separated values (CSV) files appear in many kinds of software. So do problems with CSV files. Despite decades of popularity as the most popular tabular data format, anyone who uses CSV has to deal with numerous problems. Its delimiters cause the most obvious problem with CSV: in practice, the C doesn’t always stand for comma.
Separator anxiety
Several supposedly superior delimiters aim to improve CSV by using something other than a comma to separate cells:
- semi-colons
- tabs
- ASCII record separators.
Each of these choices has some logic, but together only give us more options for saving data, and more ways for loading data to fail.
Semi-colons
Some CSV files use a semi-colon as a delimiter instead of a comma. The variant you get depends on the computer’s region settings.
Quantity,Meal,Price
3,Roast beef combo,9.95
If you load this CSV file on a computer with region settings set for the Netherlands, the software might format the price as 9,95, because Dutch uses a comma as the decimal separator. Therefore, the reasoning goes, saving this data as CSV should use a different delimiter:
Quantity;Meal;Price
3;Roast beef combo;9,95
Semi-colon delimiters belong to the category of technical design choices that seemed like a good idea at the time, but today they limit interoperability. Furthermore, semi-colons do occasionally appear in your data; changing the delimiter only achieves something when you don’t need it in your data.
Tabs
To avoid (or add to) the confusion, some files use tab characters as delimiters instead: tab-separated values (TSV). This corrupts the original use of tabs in fixed-width rather than delimited tabular data. Using tabs works nicely, as long as you don’t need tabs within values, which TSV doesn’t support.
TSV has the additional benefit that spreadsheets and other table user interfaces tend to use TSV as a clipboard format. In some software, you can paste TSV directly into a table.
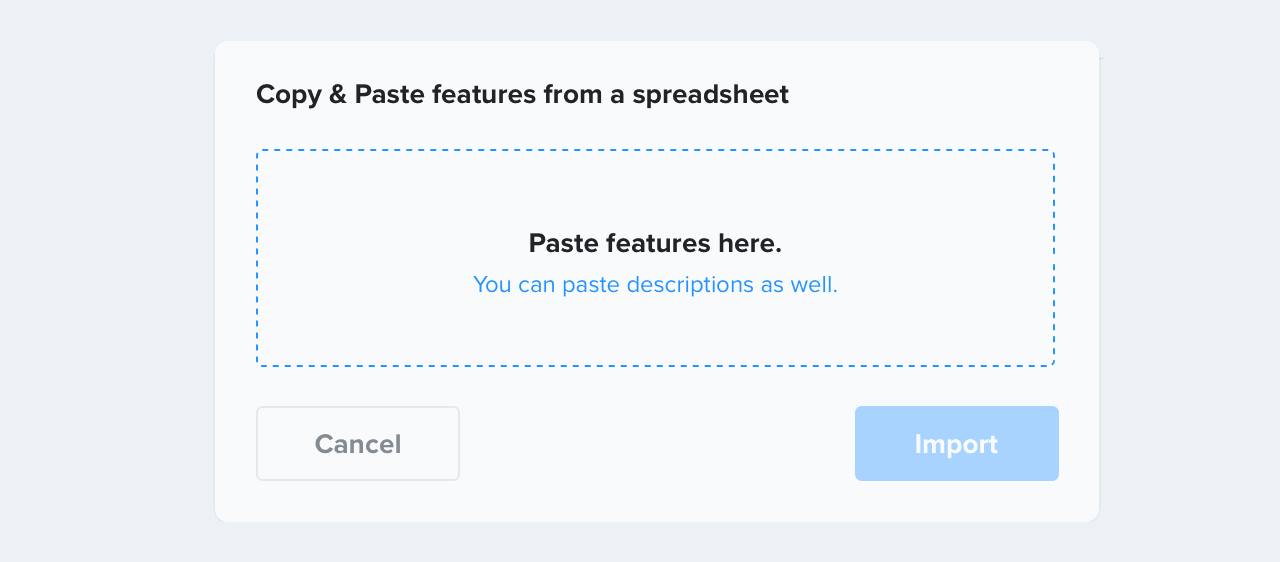
Productboard has an interesting take on this: you can paste a list of feature names and descriptions, by pasting TSV with two columns, for feature name and description, respectively. Copy/pasting from a spreadsheet like this neatly sidesteps the usual CSV import problems.
ASCII control codes
Meanwhile, ASCII Delimited Text adopts ‘the record separators defined as ASCII 28-31’. Wikipedia’s explains it better:
The use of ASCII 31 Unit separator as a field separator and ASCII 30 Record separator solves the problem of both field and record delimiters that appear in a text data stream.
This sounds like a clever way to avoid using a delimiter with other uses. However, you can’t easily recognise these control characters when you attempt to identify a CSV dialect by inspection. Which you have to do because while a so-called CSV file may use one of several dialects.
Commas
Attempts to improve CSV by using clever delimiters made it worse. Software either cannot import alternative dialects, or requires you to identify the right one; a poor user experience.
Besides, CSV delimiters don’t matter when you quote values. You might as well use a comma and quote values when you need to.
Meal,Spam score
egg and bacon,0
"egg, sausage, and bacon",0
egg and spam,1
"spam, bacon, sausage, and spam",2
But even if CSV delimiters don’t give you separator anxiety, CSV has other traps.

