What science says about naming
Computer science papers about naming (co-written with Felienne Hermans) 2016-12-26 #naming #programming
A few weeks ago we - Felienne Hermans and Peter Hilton - recorded a Software Engineering Radio podcast on naming and during and after the interview, we wondered: what does science say?! To start with, science agrees with us that naming matters. In the source code of Eclipse (about 2 MLoC) 33% of the tokens and 72% of characters are devoted to identifiers, according to Deißenbock and Pizka.
So, naming matters, but are there any cool studies out there that shine some light on what forms of naming are better than others? We decided to spend an afternoon figuring this out by reading computer science papers on naming experiments and data analyses.
But, first things first! What is good (or bad) naming?!
Defining good and bad naming
The papers we read don’t all answer the question of what constitutes a good name in the same way.
In In Quantifying Identifier Quality: An Analysis of Trends, Lawrie et al (2007) split identifiers into separate words, for example ClientWorkMngr into Client, Work and Mngr.
They then state that good identifiers are made of existing words from a dictionary, well-known abbreviations and stop words.
In Relating Identifier Naming Flaws and Code Quality: an empirical study, on the other hand, Butler et al (2009) use a list of ‘Identifier naming style guidelines’ to identify naming flaws.
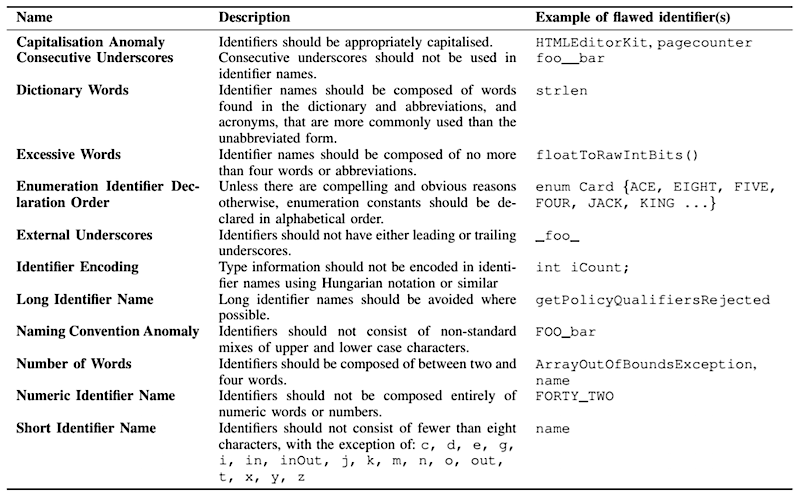
As you can see, this is a broader list than Lawrie’s, as ‘Dictionary Words’ is just one of the items on the list.
Butler takes his naming style guidelines from a presentation that Phillip Relf gave at QualCon 2004. Unfortunately, we were not able to find this presentation, called Achieving software quality through identifier names. The link in the paper is dead and we could not find him on Twitter either :( Here’s hoping that he replies to our email.
Update: Phillip Relf sent a copy of his 2004 paper, which turns out to be a good read, and potentially material for another blog post.
In Linguistic Antipatterns: What They Are and How Developers Perceive Them, Arnaoudova et al (2015) takes yet another approach. She analyzed source code from three open-source Java projects (ArgoUML, Cocoon, and Eclipse) and categorized the flaws they found into seventeen categories.

These are mostly method naming problems in which the method name does not match the method body. This differs from the kind of naming smell that identifies the kind of identifiers that causes problems regardless of context, such as abbreviations. As a result, the linguistic anti-patterns that this paper identifies are somewhat abstract, but straightforward to check for. The authors used this list to implement Linguistic Anti-Pattern Detector - an Eclipse CheckStyle plugin.
A fourth dimension of good naming is consistency. Consistency is the focus of the next paper.
In Suggesting Accurate Method and Class Names, Allamanis et al (2015) considers identifiers’ ‘naturalness’, by designing tools that make identifiers more consistent across a code base.
What matters in naming
It is interesting to see that these methods all interpret naming differently.
Lawrie inspects the words used within identifiers, but does not look at how these words are composed.
For example, in their model newMethod and new__methods_ would be the same.
Butler takes a wider look, as he does inspect the combination of words.
Both these approaches have in common that they observe identifiers in isolation, without looking at the use of a variable.
Arnaoudova does look at the context of names, but she focuses mainly on method names. Specifically focuses on the difference between the meaning of a word and its use, answering more the question of whether the method name represents its role in the program correctly, than whether the words it consists of make sense in the context. Allamanis finally prescribes no fixed rules or guidelines on the quality of names, but takes the stance that the code base itself should be leading, and that, in a sense, consistent and bad is better than good but inconsistent.
These approaches have one thing in common: they are mechanical, and in principle a program should be able to measure identifier quality. Two of the three approaches even do this, and automate identifier analysis.
A few questions that are interesting, but not really addressed by these definitions are whether a name could be ambiguous, whether a name could be more precise or whether there are overlaps between the meanings of identifier names. Fow now, though, it’s time to return to the what science says about naming and consider the papers’ findings.
Lawrie et al (2007)
In Quantifying Identifier Quality: An Analysis of Trends (PDF), Lawrie et al (2007) analyse a large amount of code to see where naming is based on dictionary words and ‘well-known’ abbreviations. This study considers several related questions about naming, leading to the following conclusions.
- Modern code makes more use of dictionary words in names, and has higher quality identifiers.
- Within a single code base, naming does not improve as the code gets older.
- Open-source code includes more names based on dictionary words than proprietary code, which includes more company-specific jargon and abbreviations.
- In general, programming language does not influence the quality of names, although Java code tends to exhibit better naming, perhaps due to the early popularity of Java coding style guidelines.
This paper’s summary starts with a conclusion that software developers would do well to take to heart.
Identifiers are clearly important to comprehending the concepts in a program. This is particularly true of comment free ‘self-documenting’ code.
The authors go on to explain that ‘identifier comprehensibility’ (i.e. meaningful names) are important, and that modern code practices and open-source software development show better naming.
Butler et al (2009)
In Relating Identifier Naming Flaws and Code Quality: an empirical study, Butler et al (2009) investigated the relationship between bad naming and bad code. Intriguingly, this study found ‘statistically significant associations’ between naming issues and code quality.
To identify naming issues, this paper compiled naming guidelines from a 2004 study by Phillip Relf:
Relf derived a set of cross-language identifier naming style guidelines from the programming literature, linking the use of typography and natural language content, and investi- gated their acceptance by programmers in an empirical study
Achieving software quality through identifier names, presented at Qualcon 2004
The resulting guidelines cover several kinds of bad naming, and styles that are inconvenient to read or maintain. The authors also selected these guidelines because they can measure them objectively.
The authors then used FindBugs to discover code quality issues, and statistical analysis to see how the two relate to each other. For example, they note that identifiers constructed of non-dictionary words are associated with ‘priority two’ FindBugs warnings.
These findings suggest that naming smells are in fact code smells in the broader sense of code that’s probably wrong, as opposed to code that’s merely hard to read, understand and maintain. However, this does not necessarily mean that improving a code base’s naming will directly resolve bugs, but it is perhaps not much of a stretch to suggest that better names will indirectly result in fewer bugs, or at least shorter fix times.
Arnaoudova et al (2015)
In Linguistic Antipatterns: What They Are and How Developers Perceive Them, Arnaoudova et al (2015) identify a number of what they call Linguistic Antipatterns - bad coding and code documentation practices.
The paper’s key findings were that 69 per cent of developers unfamiliar with the analysed code perceived instances of these linguistic anti-patterns as bad practice. By contrast, 51% of the code’s own maintainers perceived the anti-patterns as bad practice. However, the two developer groups agreed on some guidelines more than others.
Allamanis et al (2015)
In Learning Natural Coding Conventions, Allamanis et al (2015) describe their work on improving identifier names based on conventions in a given code base. Their suggestions are broader than just naming, they can also suggest improvements to formatting.
In addition to describing and evaluating Naturalize, they also shed a light on the importance of naming. The analyzed over 170 reviews with over 1000 comments and found that 9% of all comments and 25$ of all reviews contained remarks related to naming.
Naturalize uses the concept of natural source code (Hindle), and using that, it can suggest new names for locals, arguments, fields, method calls, and types. Firstly Naturalize is evaluated by testing it on existing code bases and determining whether it would results in the variable names as they are currently used. There, Naturalize achieves 94% accuracy. The authors then use it to generate 18 pull requests on existing code bases with suggestions to improve names. Of these, 14 are accepted.
We especially loved their story on a pull request for JUnit, which was not accepted, because the proposed change was not consistent with the code base, said the developers. Naturalize could then tell them all other places this convention was violated, causing the tool to suggest it!
Conclusions
It turns out that the papers referenced above are just the tip of iceberg among computer science literature on naming. We read (or skimmed) a number of related papers that take different perspectives and approaches on the naming problem.
Together, these papers paint an encouraging picture of the potential for better practical techniques that will help programmers to get better at naming, and avoid bad naming. At the same time, these papers point to numerous opportunities for better tool support for good naming, which is notably absent from mainstream software development environments.
Ironically, these papers fail to agree on one thing: the best name for bad naming. They variously refer to naming bugs, identifier flaws, linguistic anti-patterns, and none of them use Peter’s ‘naming smells’ name. It’s too bad that academic papers don’t have Rename refactoring.

